On fixing embedded content in WordPress
How to use a custom wpcli command to fix broken links in all content across your entire WordPress site.


Even though my main occupation nowadays is fixing sites through Mindsize, I still have a small circle of clients I like to work with on an as-needed basis. One of them is MIGHTYminnow.
They had a client whose site was migrated onto a new WordPress installation. There was just one problem: files uploaded and links to them in content were not escaped, so none of the links pointed to the actual files. They were full of %20 and other non-standard characters. On top of that none of the files that those links were supposed to link to were actually present in the media library, though they were physically on the server.
There were therefore two tasks ahead: to import the files into the media library, and to sanitize the links in the content.
Files into media library
There was a plugin on the site called add-from-server, which, as its name suggests, adds the file from the server into the media library and depending on what setting you chose, moves the file into the appropriate folders. However upon experimentation with the plugin, the following drawbacks kept me from using it as is:
- it doesn’t actually sanitize the filename when moving. It literally just adds the file, as is, into the media library, completely sidestepping the renaming of the file when you just upload one from your computer. So a file named
This is a report for the final weeks of 2008 id=1234.pdfwill stay as is instead of being renamedThis-is-a-report-for-the-final-weeks-of-2008-id1234.pdf. The function that does this in WordPress issanitize_file_name - it’s not an AJAX script, which means if you select a lot of files to be processed, it might take a while, and on some (most) hosts this process would be killed because it takes longer than their long-running-script-cutoff time. That’s obviously not great at this point because I was dealing with 800-odd files.
These two meant that I had to rewrite parts of the plugin to get the files in to the library correctly.
First I isolated which part I need to rewrite by looking at the code of the plugin itself. A few well placed logging messages (trigger_error in its simplest form) helped a lot too. I experimented with importing one file at a time, figuring out where I was in the code based on the trigger_error messages, then deleting the media library entry. The file wasn’t moved at this point.
Then I had to figure out what it was actually doing. Luckily it already handled the heavy lifting of adding the file itself to the database (aka the media library), so all I had to do was to rename the file.
Because I opted for moving the file to where a file would be moved if it was uploaded, I had to copy and rename the file. Technically the plugin has the option to move the file per current time, or per the file’s time, which means leaving it in place.
Practically this meant that if the file was in the wp-content/uploads/2017/09 folder, it would be moved to the wp-content/uploads/2018/01 folder.
Then I needed to extract only the filename, figure out the path’s non-filename part, sanitize the filename, stitch it together, and move it. The code for that is thus:
// part of the add-from-server.php
...
// Is the file allready in the uploads folder?
// WP < 4.4 Compat: ucfirst
if ( preg_match( '|^' . preg_quote( ucfirst( wp_normalize_path( $uploads['basedir'] ) ), '|' ) . '(.*)$|i', $file, $mat ) ) {
/**
* The pipe | is the boundary character here
* $uploads['basedir'] = /Users/javorszky/Sites/dev/wp-content/uploads
* wp_normalize_path( $uploads['basedir'] ) = /Users/javorszky/Sites/dev/wp-content/uploads
*
* Basically = is the last bit of the path pointing to the file
*/
$filename = sanitize_file_name( basename( $file ) );
$new_file = $uploads['path'] . DIRECTORY_SEPARATOR . $filename;
if ( ! copy( $file, $new_file ) ) {
return new WP_Error( 'copy_error', 'Sorry, could not copy the file with its sanitized name.' );
}
// delete the old file
// unlink( $file );
$url = $uploads['url'] . DIRECTORY_SEPARATOR . $filename;
At this point I already have access to the variable $file, which is the full path of the file’s current (broken) path.
Then I construct the target location based on what the uploads folder / url should be, copy the file, and let the rest of the script carry on with what it does.
NOTE: Technically I could have deleted the old file from the old location. I didn’t, in case something went wrong and we needed the original. Yes, despite the fact that at this point there were at least 3 backups.
So this takes care of moving the file into a new location, now with sanitized filename, and inserted that into the media library.
Fixing content links
The content originally had links that looked like this:
<a href="/wp-content/2017/09/File%20Name%20Thats%20Got%20Unsanitized%20Names%20id=1234.pdf">Link text</a>
The following needs to happen to this link:
- replace all
%20with a dash- - strip out every
= - add the site’s full url in front of
/wp-content, but only if it’s missing - strip out all
+from the names - replace all spaces with a dash
Essentially I needed to sanitize the filename as well.
wp search-replace
This command is AWESOME, because it can do regex replaces across everything! The problem was coming up with a regex robust enough to be able replace multiple things that are arbitrarily placed in a string, but that is contained within two fixed strings.
Long story short, I learned a lot of useful things about regexes: things like lookahead, backreference, named references, non-matching groups, and so on, but the closest I got was this: https://regex101.com/r/qkLeMP/3
I can match the entire filename, but I can’t match the individual spaces, let alone use those references to replace them with dashes.
So let’s rethink this.
custom wp command
After having talked to a bunch of people, I looked at how wp search-replace works to see whether I can use some of the code and tinker with it. Turns out it literally fetches everything from each table (unless you excluded them), and then loops over all the column values (except the ID ones), and then depending on what kind of replace you’re doing, either does a str_replace or a preg_replace on the data.
Easy.
So I copied the command, ripped out some parts, and modified it to suit my needs. Essentially my version will
- loop through all tables, like
search-replace - grab all data from all columns minus IDs, like
search-replace - and then match all link hrefs in the data. From this point it’s different to
search-replace. The regex to match all links is this (reason it looks like that is because I needed to escape it forpreg_replace_callback1:
'/<a(?:.*?)href=\\\\?"(.*?\.(?:\w{3,4}))\\\\?"[ |>]/';
- once I have all links, I go through a few steps of sanitization:
- first I check whether it’s an escaped url, that’s not encoded as json. I check whether the data is json by trying to
json_decode( $data ), and if it’s true, I’ll set a flag that the content is json. If it’s an escaped url, but it’s not json, I’ll fix the escapes - I’ll check whether this is an absolute or a relative url. Does it begin with
/wp-content? It’s a relative one. I then putget_home_url()in front of it. - Is this an external link? Does it begin with
get_home_url()? If not, I move on to the next one. I don’t want to mess with links that point to Google... - And then I’ll look for the files only. Files that match the following regex, and if there aren’t any, the link is returned.
'/wp-content\/uploads\/\d{4}\/\d{2}\/(.*?\.(?:pdf|doc|docx|dotx|wmv|wma|ppt|pptx|xlsx|xls|m4a))/';
- At this point we have an absolute url with an uploaded file. I then explode it by the
/, and pop the last part as the file itself. - Then I call
urldecodeon it, because I want to turn%20into spaces. Otherwise the next step will produce bad results 2 - And then I call
sanitize_file_nameon the file, put it back to the parts array, and glue them together by/ - If the content was json, I’ll
wp_json_encodethe new url - and then I simply replace the original url with the new one in the link. Remember, the matched link is the entire
<a>tag, with everything - and then finally, return it
This process was a lot more robust than having to come up with one regex that would have achieved all of this.
Along the way I bumped into a weird quirk in sanitize_file_name where it strips the % first, and then turns all %20 into dashes. So my thought was that that will never happen.
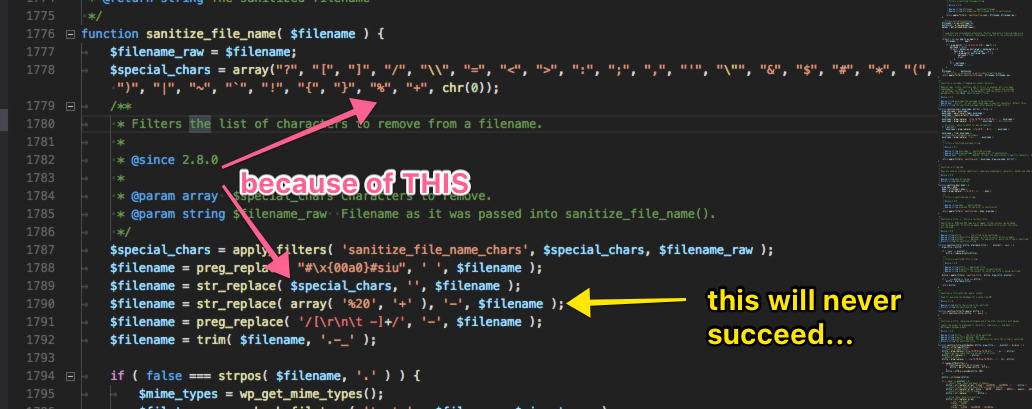
Turns out the because it’s for files, the chances of them having %20 in the file name is small. Also people can filter the list of special characters and remove % from the chars replaced, so...
Major props to the following people who have helped me in this by either trying to solve the one-regex-to-rule-them-all thing, figuring out why sanitize_file_name does things in the order it does, or gently nudging me towards writing a custom command: Garth Mortensen, Alain Schlesser, Dan Beil, Sam Brasseale, Slava Abakumov, Daniel Bachhuber, Brett Shumaker, Ryan McCue. Thank you all! 🙏
[1] The regex there would be <a(?:.*?)href=\\?"(.*?\.(?:\w{3,4}))\\?"[ |>] by itself. You can plug this into regex101 and test against a bunch of links. My test string was
<a class="foo" href="/wp-content/2017/09/some file %20id=3242.pdf" target="_blank">
It basically means this:
“get me an a tag that has anything after <a, then followed by href= where we might or might not find a \, then a ", then anything, followed by a literal . character, then followed by 3 or 4 word characters (file extension), then maybe a \, then a ", and then either space, or a closing >, and give me the bit between the href=" and "> (ie the actual link).”
[2] The WordPress-Extra coding standards suggest we should use rawurldecode instead of urldecode, so in the code I’ve done that. Because sanitize_file_name works on file names, and not urls, first I had to make the URLs behave like file names. Hence the need to use the urldecode functions.
Photo by Ruben Mishchuk on Unsplash